

How To Add Letter To Edge In Graphviz In Python
How to Develop a Neural Automobile Translation System from Scratch
Final Updated on October six, 2020
Develop a Deep Learning Model to Automatically
Translate from German to English in Python with Keras, Footstep-past-Step.
Machine translation is a challenging task that traditionally involves big statistical models adult using highly sophisticated linguistic knowledge.
Neural car translation is the use of deep neural networks for the trouble of motorcar translation.
In this tutorial, you will discover how to develop a neural motorcar translation system for translating German phrases to English.
After completing this tutorial, yous will know:
- How to clean and prepare information prepare to railroad train a neural machine translation organization.
- How to develop an encoder-decoder model for motorcar translation.
- How to use a trained model for inference on new input phrases and evaluate the model skill.
Kicking-commencement your project with my new book Deep Learning for Natural Linguistic communication Processing, including step-by-step tutorials and the Python source code files for all examples.
Permit's get started.
- Update Apr/2019: Fixed problems in the adding of BLEU score (Zhongpu Chen).
- Update October/2020: Added directly link to original dataset.

How to Develop a Neural Auto Translation Organisation in Keras
Photograph by Björn Groß, some rights reserved.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
- German to English language Translation Dataset
- Preparing the Text Data
- Train Neural Translation Model
- Evaluate Neural Translation Model
Python Environment
This tutorial assumes you lot have a Python 3 SciPy surround installed.
You must have Keras (2.0 or college) installed with either the TensorFlow or Theano backend.
The tutorial too assumes you have NumPy and Matplotlib installed.
If yous need help with your environment, see this post:
- How to Setup a Python Surroundings for Deep Learning
A GPU is not require for thus tutorial, nevertheless, you tin access GPUs cheaply on Amazon Web Services. Learn how in this tutorial:
- How to Setup Amazon AWS EC2 GPUs for Deep Learning (step-by-step)
Let'southward dive in.
Need help with Deep Learning for Text Information?
Accept my gratuitous vii-day email crash grade now (with lawmaking).
Click to sign-upwardly and also get a free PDF Ebook version of the course.
German to English Translation Dataset
In this tutorial, we will use a dataset of German language to English terms used equally the basis for flashcards for language learning.
The dataset is available from the ManyThings.org website, with examples drawn from the Tatoeba Project. The dataset is comprised of German phrases and their English counterparts and is intended to be used with the Anki flashcard software.
The page provides a list of many language pairs, and I encourage y'all to explore other languages:
- Tab-delimited Bilingual Judgement Pairs
Notation, the original dataset has inverse which if used directly will break this tutorial and result in an error:
| ValueError: too many values to unpack (expected 2) |
As such you lot can download the original dataset in the correct format directly from here:
- German to English Translation (deu-eng.txt)
- High german to English Translation Description (deu-eng.names)
Download the dataset file to your electric current working directory.
You will have a file chosen deu.txt that contains 152,820 pairs of English to High german phases, 1 pair per line with a tab separating the language.
For example, the offset 5 lines of the file look as follows:
| How-do-you-do. Hallo! Hi. Grüß Gott! Run! Lauf! Wow! Potzdonner! Wow! Donnerwetter! |
We volition frame the prediction problem as given a sequence of words in German language as input, interpret or predict the sequence of words in English language.
The model nosotros will develop volition be suitable for some beginner German phrases.
Preparing the Text Information
The next step is to prepare the text data ready for modeling.
If you lot are new to cleaning text data, see this post:
- How to Clean Text for Machine Learning with Python
Take a look at the raw data and notation what you see that we might demand to handle in a data cleaning performance.
For case, hither are some observations I note from reviewing the raw information:
- There is punctuation.
- The text contains uppercase and lowercase.
- There are special characters in the German language.
- There are duplicate phrases in English with different translations in German.
- The file is ordered by sentence length with very long sentences toward the cease of the file.
Did you notation anything else that could be important?
Let me know in the comments beneath.
A skilful text cleaning procedure may handle some or all of these observations.
Information preparation is divided into two subsections:
- Clean Text
- Split Text
one. Clean Text
Commencement, we must load the information in a fashion that preserves the Unicode German language characters. The function below called load_doc() will load the file equally a hulk of text.
| # load doc into retention def load_doc ( filename ) : # open the file as read simply file = open ( filename , fashion = 'rt' , encoding = 'utf-8' ) # read all text text = file . read ( ) # close the file file . close ( ) return text |
Each line contains a single pair of phrases, offset English and so German, separated past a tab character.
We must split the loaded text by line and then past phrase. The part to_pairs() below will split the loaded text.
| # carve up a loaded document into sentences def to_pairs ( doc ) : lines = doc . strip ( ) . split ( '\n' ) pairs = [ line . separate ( '\t' ) for line in lines ] return pairs |
We are now set up to make clean each judgement. The specific cleaning operations nosotros will perform are every bit follows:
- Remove all not-printable characters.
- Remove all punctuation characters.
- Normalize all Unicode characters to ASCII (east.g. Latin characters).
- Normalize the case to lowercase.
- Remove whatsoever remaining tokens that are non alphabetic.
We volition perform these operations on each phrase for each pair in the loaded dataset.
The clean_pairs() office beneath implements these operations.
| 1 ii iii 4 v 6 vii 8 9 10 eleven 12 xiii 14 fifteen 16 17 eighteen 19 20 21 22 23 24 25 26 27 | # clean a list of lines def clean_pairs ( lines ) : cleaned = list ( ) # ready regex for char filtering re_print = re . compile ( '[^%southward]' % re . escape ( string . printable ) ) # prepare translation table for removing punctuation table = str . maketrans ( '' , '' , string . punctuation ) for pair in lines : clean_pair = list ( ) for line in pair : # normalize unicode characters line = normalize ( 'NFD' , line ) . encode ( 'ascii' , 'ignore' ) line = line . decode ( 'UTF-8' ) # tokenize on white space line = line . carve up ( ) # convert to lowercase line = [ discussion . lower ( ) for word in line ] # remove punctuation from each token line = [ discussion . translate ( table ) for discussion in line ] # remove not-printable chars form each token line = [ re_print . sub ( '' , west ) for due west in line ] # remove tokens with numbers in them line = [ word for word in line if word . isalpha ( ) ] # store as string clean_pair . append ( ' ' . join ( line ) ) cleaned . append ( clean_pair ) return array ( cleaned ) |
Finally, now that the information has been cleaned, nosotros can relieve the listing of phrase pairs to a file gear up for employ.
The function save_clean_data() uses the pickle API to save the listing of clean text to file.
Pulling all of this together, the complete example is listed beneath.
| 1 2 iii 4 five vi 7 eight 9 10 eleven 12 thirteen 14 15 xvi 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | import string import re from pickle import dump from unicodedata import normalize from numpy import array # load md into memory def load_doc ( filename ) : # open the file as read only file = open ( filename , manner = 'rt' , encoding = 'utf-eight' ) # read all text text = file . read ( ) # close the file file . close ( ) return text # split a loaded certificate into sentences def to_pairs ( doc ) : lines = doc . strip ( ) . split ( '\n' ) pairs = [ line . carve up ( '\t' ) for line in lines ] return pairs # clean a list of lines def clean_pairs ( lines ) : cleaned = list ( ) # prepare regex for char filtering re_print = re . compile ( '[^%southward]' % re . escape ( string . printable ) ) # prepare translation table for removing punctuation table = str . maketrans ( '' , '' , string . punctuation ) for pair in lines : clean_pair = listing ( ) for line in pair : # normalize unicode characters line = normalize ( 'NFD' , line ) . encode ( 'ascii' , 'ignore' ) line = line . decode ( 'UTF-8' ) # tokenize on white infinite line = line . split ( ) # convert to lowercase line = [ word . lower ( ) for word in line ] # remove punctuation from each token line = [ word . translate ( tabular array ) for discussion in line ] # remove non-printable chars form each token line = [ re_print . sub ( '' , westward ) for west in line ] # remove tokens with numbers in them line = [ word for word in line if word . isalpha ( ) ] # store every bit string clean_pair . suspend ( ' ' . join ( line ) ) cleaned . append ( clean_pair ) return array ( cleaned ) # save a list of clean sentences to file def save_clean_data ( sentences , filename ) : dump ( sentences , open ( filename , 'wb' ) ) print ( 'Saved: %south' % filename ) # load dataset filename = 'deu.txt' dr. = load_doc ( filename ) # split into english-german pairs pairs = to_pairs ( doc ) # clean sentences clean_pairs = clean_pairs ( pairs ) # salve make clean pairs to file save_clean_data ( clean_pairs , 'english-german.pkl' ) # spot cheque for i in range ( 100 ) : print ( '[%s] => [%s]' % ( clean_pairs [ i , 0 ] , clean_pairs [ i , one ] ) ) |
Running the example creates a new file in the current working directory with the cleaned text called english-high german.pkl.
Some examples of the clean text are printed for us to evaluate at the stop of the run to confirm that the clean operations were performed as expected.
| [hi] => [hallo] [hi] => [gru gott] [run] => [lauf] [wow] => [potzdonner] [wow] => [donnerwetter] [fire] => [feuer] [help] => [hilfe] [help] => [zu hulf] [stop] => [stopp] [wait] => [warte] ... |
ii. Split up Text
The clean data contains a piffling over 150,000 phrase pairs and some of the pairs toward the end of the file are very long.
This is a adept number of examples for developing a small translation model. The complexity of the model increases with the number of examples, length of phrases, and size of the vocabulary.
Although nosotros have a good dataset for modeling translation, we volition simplify the problem slightly to dramatically reduce the size of the model required, and in turn the preparation time required to fit the model.
Y'all tin explore developing a model on the fuller dataset as an extension; I would dear to hear how you do.
We volition simplify the problem past reducing the dataset to the first 10,000 examples in the file; these will exist the shortest phrases in the dataset.
Further, we will then pale the first 9,000 of those every bit examples for training and the remaining i,000 examples to test the fit model.
Below is the consummate example of loading the clean data, splitting it, and saving the split portions of data to new files.
| ane 2 3 iv 5 vi 7 eight nine x 11 12 xiii 14 fifteen 16 17 eighteen 19 twenty 21 22 23 24 25 26 27 28 | from pickle import load from pickle import dump from numpy . random import rand from numpy . random import shuffle # load a clean dataset def load_clean_sentences ( filename ) : return load ( open ( filename , 'rb' ) ) # relieve a list of clean sentences to file def save_clean_data ( sentences , filename ) : dump ( sentences , open ( filename , 'wb' ) ) print ( 'Saved: %s' % filename ) # load dataset raw_dataset = load_clean_sentences ( 'english-german language.pkl' ) # reduce dataset size n_sentences = 10000 dataset = raw_dataset [ : n_sentences , : ] # random shuffle shuffle ( dataset ) # carve up into train/exam railroad train , test = dataset [ : 9000 ] , dataset [ 9000 : ] # save save_clean_data ( dataset , 'english-german-both.pkl' ) save_clean_data ( railroad train , 'english-german-train.pkl' ) save_clean_data ( examination , 'english language-german-examination.pkl' ) |
Running the instance creates iii new files: the english-german-both.pkl that contains all of the railroad train and test examples that nosotros can employ to ascertain the parameters of the trouble, such as max phrase lengths and the vocabulary, and the english-german-railroad train.pkl and english language-german language-test.pkl files for the train and test dataset.
Nosotros are now set to beginning developing our translation model.
Train Neural Translation Model
In this section, nosotros volition develop the neural translation model.
If you are new to neural translation models, see the postal service:
- A Gentle Introduction to Neural Machine Translation
This involves both loading and preparing the clean text information ready for modeling and defining and training the model on the prepared information.
Let'due south start off by loading the datasets so that we can prepare the data. The function below named load_clean_sentences() can be used to load the train, examination, and both datasets in turn.
| # load a clean dataset def load_clean_sentences ( filename ) : render load ( open ( filename , 'rb' ) ) # load datasets dataset = load_clean_sentences ( 'english-german-both.pkl' ) train = load_clean_sentences ( 'english-high german-train.pkl' ) test = load_clean_sentences ( 'english-high german-test.pkl' ) |
We will use the "both" or combination of the train and test datasets to define the maximum length and vocabulary of the problem.
This is for simplicity. Alternately, we could define these properties from the training dataset alone and truncate examples in the test fix that are too long or have words that are out of the vocabulary.
We tin can use the Keras Tokenize grade to map words to integers, as needed for modeling. We volition use split up tokenizer for the English language sequences and the German sequences. The part below-named create_tokenizer() will train a tokenizer on a list of phrases.
| # fit a tokenizer def create_tokenizer ( lines ) : tokenizer = Tokenizer ( ) tokenizer . fit_on_texts ( lines ) render tokenizer |
Similarly, the role named max_length() below will find the length of the longest sequence in a list of phrases.
| # max sentence length def max_length ( lines ) : return max ( len ( line . split ( ) ) for line in lines ) |
Nosotros can call these functions with the combined dataset to gear up tokenizers, vocabulary sizes, and maximum lengths for both the English and German language phrases.
| # prepare english tokenizer eng_tokenizer = create_tokenizer ( dataset [ : , 0 ] ) eng_vocab_size = len ( eng_tokenizer . word_index ) + ane eng_length = max_length ( dataset [ : , 0 ] ) print ( 'English Vocabulary Size: %d' % eng_vocab_size ) print ( 'English Max Length: %d' % ( eng_length ) ) # prepare high german tokenizer ger_tokenizer = create_tokenizer ( dataset [ : , 1 ] ) ger_vocab_size = len ( ger_tokenizer . word_index ) + 1 ger_length = max_length ( dataset [ : , 1 ] ) print ( 'High german Vocabulary Size: %d' % ger_vocab_size ) impress ( 'High german Max Length: %d' % ( ger_length ) ) |
Nosotros are now gear up to prepare the preparation dataset.
Each input and output sequence must be encoded to integers and padded to the maximum phrase length. This is because we will use a word embedding for the input sequences and one hot encode the output sequences The office below named encode_sequences() will perform these operations and return the result.
| # encode and pad sequences def encode_sequences ( tokenizer , length , lines ) : # integer encode sequences Ten = tokenizer . texts_to_sequences ( lines ) # pad sequences with 0 values 10 = pad_sequences ( 10 , maxlen = length , padding = 'post' ) return Ten |
The output sequence needs to exist one-hot encoded. This is because the model will predict the probability of each word in the vocabulary as output.
The function encode_output() beneath will one-hot encode English language output sequences.
| # ane hot encode target sequence def encode_output ( sequences , vocab_size ) : ylist = list ( ) for sequence in sequences : encoded = to_categorical ( sequence , num_classes = vocab_size ) ylist . append ( encoded ) y = array ( ylist ) y = y . reshape ( sequences . shape [ 0 ] , sequences . shape [ 1 ] , vocab_size ) render y |
We can brand utilise of these two functions and prepare both the train and test dataset set for training the model.
| # prepare training data trainX = encode_sequences ( ger_tokenizer , ger_length , railroad train [ : , ane ] ) trainY = encode_sequences ( eng_tokenizer , eng_length , train [ : , 0 ] ) trainY = encode_output ( trainY , eng_vocab_size ) # fix validation data testX = encode_sequences ( ger_tokenizer , ger_length , test [ : , 1 ] ) testY = encode_sequences ( eng_tokenizer , eng_length , test [ : , 0 ] ) testY = encode_output ( testY , eng_vocab_size ) |
We are now ready to define the model.
We will use an encoder-decoder LSTM model on this problem. In this architecture, the input sequence is encoded by a front-end model called the encoder then decoded word by word by a backend model chosen the decoder.
The role define_model() below defines the model and takes a number of arguments used to configure the model, such equally the size of the input and output vocabularies, the maximum length of input and output phrases, and the number of retention units used to configure the model.
The model is trained using the efficient Adam approach to stochastic gradient descent and minimizes the categorical loss function because we have framed the prediction trouble as multi-class classification.
The model configuration was not optimized for this problem, meaning that there is enough of opportunity for you to tune it and lift the skill of the translations. I would honey to see what you can come with.
For more advice on configuring neural machine translation models, see the post:
- How to Configure an Encoder-Decoder Model for Neural Motorcar Translation
| # ascertain NMT model def define_model ( src_vocab , tar_vocab , src_timesteps , tar_timesteps , n_units ) : model = Sequential ( ) model . add together ( Embedding ( src_vocab , n_units , input_length = src_timesteps , mask_zero = True ) ) model . add ( LSTM ( n_units ) ) model . add ( RepeatVector ( tar_timesteps ) ) model . add ( LSTM ( n_units , return_sequences = Truthful ) ) model . add ( TimeDistributed ( Dense ( tar_vocab , activation = 'softmax' ) ) ) return model # define model model = define_model ( ger_vocab_size , eng_vocab_size , ger_length , eng_length , 256 ) model . compile ( optimizer = 'adam' , loss = 'categorical_crossentropy' ) # summarize defined model print ( model . summary ( ) ) plot_model ( model , to_file = 'model.png' , show_shapes = True ) |
Finally, we can train the model.
Nosotros train the model for xxx epochs and a batch size of 64 examples.
We employ checkpointing to ensure that each time the model skill on the test set improves, the model is saved to file.
| # fit model filename = 'model.h5' checkpoint = ModelCheckpoint ( filename , monitor = 'val_loss' , verbose = 1 , save_best_only = True , style = 'min' ) model . fit ( trainX , trainY , epochs = thirty , batch_size = 64 , validation_data = ( testX , testY ) , callbacks = [ checkpoint ] , verbose = two ) |
We tin can necktie all of this together and fit the neural translation model.
The complete working example is listed beneath.
| 1 2 3 four v half dozen 7 8 9 10 xi 12 13 xiv 15 16 17 eighteen 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 threescore 61 62 63 64 65 66 67 68 69 seventy 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | from pickle import load from numpy import array from keras . preprocessing . text import Tokenizer from keras . preprocessing . sequence import pad_sequences from keras . utils import to_categorical from keras . utils . vis_utils import plot_model from keras . models import Sequential from keras . layers import LSTM from keras . layers import Dense from keras . layers import Embedding from keras . layers import RepeatVector from keras . layers import TimeDistributed from keras . callbacks import ModelCheckpoint # load a make clean dataset def load_clean_sentences ( filename ) : return load ( open ( filename , 'rb' ) ) # fit a tokenizer def create_tokenizer ( lines ) : tokenizer = Tokenizer ( ) tokenizer . fit_on_texts ( lines ) return tokenizer # max sentence length def max_length ( lines ) : return max ( len ( line . split ( ) ) for line in lines ) # encode and pad sequences def encode_sequences ( tokenizer , length , lines ) : # integer encode sequences X = tokenizer . texts_to_sequences ( lines ) # pad sequences with 0 values X = pad_sequences ( X , maxlen = length , padding = 'post' ) return Ten # one hot encode target sequence def encode_output ( sequences , vocab_size ) : ylist = list ( ) for sequence in sequences : encoded = to_categorical ( sequence , num_classes = vocab_size ) ylist . append ( encoded ) y = assortment ( ylist ) y = y . reshape ( sequences . shape [ 0 ] , sequences . shape [ ane ] , vocab_size ) return y # define NMT model def define_model ( src_vocab , tar_vocab , src_timesteps , tar_timesteps , n_units ) : model = Sequential ( ) model . add together ( Embedding ( src_vocab , n_units , input_length = src_timesteps , mask_zero = True ) ) model . add ( LSTM ( n_units ) ) model . add ( RepeatVector ( tar_timesteps ) ) model . add together ( LSTM ( n_units , return_sequences = True ) ) model . add together ( TimeDistributed ( Dumbo ( tar_vocab , activation = 'softmax' ) ) ) return model # load datasets dataset = load_clean_sentences ( 'english language-german-both.pkl' ) train = load_clean_sentences ( 'english-german-train.pkl' ) examination = load_clean_sentences ( 'english-german-test.pkl' ) # prepare english tokenizer eng_tokenizer = create_tokenizer ( dataset [ : , 0 ] ) eng_vocab_size = len ( eng_tokenizer . word_index ) + 1 eng_length = max_length ( dataset [ : , 0 ] ) impress ( 'English Vocabulary Size: %d' % eng_vocab_size ) print ( 'English Max Length: %d' % ( eng_length ) ) # prepare german tokenizer ger_tokenizer = create_tokenizer ( dataset [ : , 1 ] ) ger_vocab_size = len ( ger_tokenizer . word_index ) + i ger_length = max_length ( dataset [ : , 1 ] ) print ( 'German language Vocabulary Size: %d' % ger_vocab_size ) impress ( 'German language Max Length: %d' % ( ger_length ) ) # set training data trainX = encode_sequences ( ger_tokenizer , ger_length , train [ : , i ] ) trainY = encode_sequences ( eng_tokenizer , eng_length , train [ : , 0 ] ) trainY = encode_output ( trainY , eng_vocab_size ) # fix validation information testX = encode_sequences ( ger_tokenizer , ger_length , exam [ : , 1 ] ) testY = encode_sequences ( eng_tokenizer , eng_length , test [ : , 0 ] ) testY = encode_output ( testY , eng_vocab_size ) # ascertain model model = define_model ( ger_vocab_size , eng_vocab_size , ger_length , eng_length , 256 ) model . compile ( optimizer = 'adam' , loss = 'categorical_crossentropy' ) # summarize divers model print ( model . summary ( ) ) plot_model ( model , to_file = 'model.png' , show_shapes = True ) # fit model filename = 'model.h5' checkpoint = ModelCheckpoint ( filename , monitor = 'val_loss' , verbose = 1 , save_best_only = True , mode = 'min' ) model . fit ( trainX , trainY , epochs = 30 , batch_size = 64 , validation_data = ( testX , testY ) , callbacks = [ checkpoint ] , verbose = two ) |
Running the instance first prints a summary of the parameters of the dataset such equally vocabulary size and maximum phrase lengths.
| English language Vocabulary Size: 2404 English Max Length: 5 German language Vocabulary Size: 3856 High german Max Length: 10 |
Next, a summary of the defined model is printed, assuasive usa to confirm the model configuration.
| one 2 3 4 5 6 7 viii 9 ten 11 12 thirteen 14 fifteen 16 17 | _________________________________________________________________ Layer (blazon) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 10, 256) 987136 _________________________________________________________________ lstm_1 (LSTM) (None, 256) 525312 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, five, 256) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 5, 256) 525312 _________________________________________________________________ time_distributed_1 (TimeDist (None, 5, 2404) 617828 ================================================================= Total params: 2,655,588 Trainable params: two,655,588 Non-trainable params: 0 _________________________________________________________________ |
A plot of the model is too created providing another perspective on the model configuration.
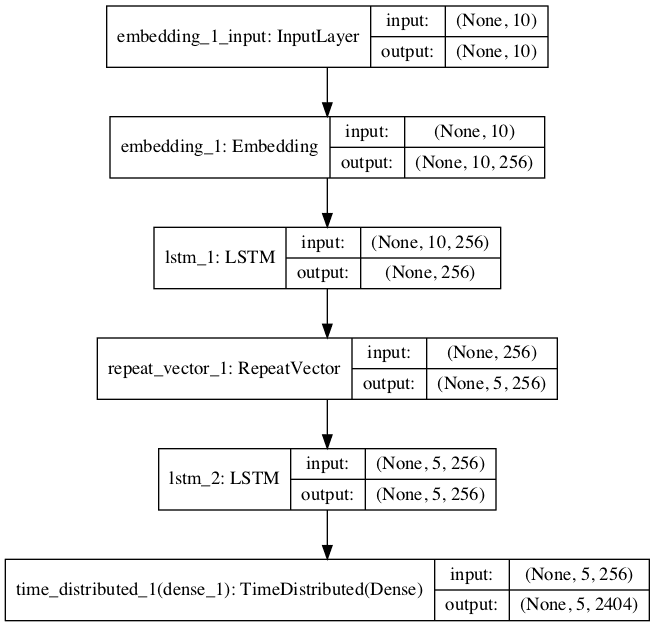
Plot of Model Graph for NMT
Next, the model is trained.
Each epoch takes near 30 seconds on modern CPU hardware; no GPU is required.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation process, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
During the run, the model will be saved to the file model.h5, ready for inference in the adjacent step.
| ... Epoch 26/30 Epoch 00025: val_loss improved from ii.20048 to two.19976, saving model to model.h5 17s - loss: 0.7114 - val_loss: 2.1998 Epoch 27/30 Epoch 00026: val_loss improved from two.19976 to 2.18255, saving model to model.h5 17s - loss: 0.6532 - val_loss: 2.1826 Epoch 28/30 Epoch 00027: val_loss did not improve 17s - loss: 0.5970 - val_loss: 2.1970 Epoch 29/30 Epoch 00028: val_loss improved from ii.18255 to ii.17872, saving model to model.h5 17s - loss: 0.5474 - val_loss: 2.1787 Epoch 30/30 Epoch 00029: val_loss did not amend 17s - loss: 0.5023 - val_loss: 2.1823 |
Evaluate Neural Translation Model
Nosotros volition evaluate the model on the train and the test dataset.
The model should perform very well on the railroad train dataset and ideally have been generalized to perform well on the test dataset.
Ideally, we would use a separate validation dataset to help with model selection during preparation instead of the examination ready. You can try this as an extension.
The make clean datasets must be loaded and prepared as before.
| . . . # load datasets dataset = load_clean_sentences ( 'english-german language-both.pkl' ) train = load_clean_sentences ( 'english language-german-train.pkl' ) examination = load_clean_sentences ( 'english language-german-examination.pkl' ) # prepare english tokenizer eng_tokenizer = create_tokenizer ( dataset [ : , 0 ] ) eng_vocab_size = len ( eng_tokenizer . word_index ) + 1 eng_length = max_length ( dataset [ : , 0 ] ) # set up german tokenizer ger_tokenizer = create_tokenizer ( dataset [ : , 1 ] ) ger_vocab_size = len ( ger_tokenizer . word_index ) + 1 ger_length = max_length ( dataset [ : , 1 ] ) # fix data trainX = encode_sequences ( ger_tokenizer , ger_length , railroad train [ : , ane ] ) testX = encode_sequences ( ger_tokenizer , ger_length , test [ : , 1 ] ) |
Next, the all-time model saved during preparation must be loaded.
| # load model model = load_model ( 'model.h5' ) |
Evaluation involves two steps: get-go generating a translated output sequence, and then repeating this process for many input examples and summarizing the skill of the model across multiple cases.
Starting with inference, the model can predict the entire output sequence in a i-shot manner.
| translation = model . predict ( source , verbose = 0 ) |
This will be a sequence of integers that we tin enumerate and lookup in the tokenizer to map back to words.
The office below, named word_for_id(), will perform this contrary mapping.
| # map an integer to a word def word_for_id ( integer , tokenizer ) : for word , alphabetize in tokenizer . word_index . items ( ) : if index == integer : return word return None |
We tin perform this mapping for each integer in the translation and return the upshot as a string of words.
The function predict_sequence() below performs this operation for a single encoded source phrase.
| # generate target given source sequence def predict_sequence ( model , tokenizer , source ) : prediction = model . predict ( source , verbose = 0 ) [ 0 ] integers = [ argmax ( vector ) for vector in prediction ] target = list ( ) for i in integers : word = word_for_id ( i , tokenizer ) if word is None : break target . append ( word ) return ' ' . join ( target ) |
Next, we tin repeat this for each source phrase in a dataset and compare the predicted result to the expected target phrase in English.
Nosotros can print some of these comparisons to screen to get an thought of how the model performs in practice.
We volition as well calculate the BLEU scores to get a quantitative idea of how well the model has performed.
You can acquire more about the BLEU score here:
- A Gentle Introduction to Computing the BLEU Score for Text in Python
The evaluate_model() function below implements this, calling the above predict_sequence() function for each phrase in a provided dataset.
| ane two 3 iv 5 six seven 8 9 x eleven 12 13 14 15 16 17 | # evaluate the skill of the model def evaluate_model ( model , tokenizer , sources , raw_dataset ) : bodily , predicted = list ( ) , list ( ) for i , source in enumerate ( sources ) : # translate encoded source text source = source . reshape ( ( 1 , source . shape [ 0 ] ) ) translation = predict_sequence ( model , eng_tokenizer , source ) raw_target , raw_src = raw_dataset [ i ] if i < 10 : print ( 'src=[%southward], target=[%southward], predicted=[%south]' % ( raw_src , raw_target , translation ) ) actual . append ( [ raw_target . dissever ( ) ] ) predicted . append ( translation . split ( ) ) # calculate BLEU score print ( 'BLEU-1: %f' % corpus_bleu ( actual , predicted , weights = ( ane.0 , 0 , 0 , 0 ) ) ) print ( 'BLEU-2: %f' % corpus_bleu ( actual , predicted , weights = ( 0.5 , 0.5 , 0 , 0 ) ) ) print ( 'BLEU-3: %f' % corpus_bleu ( actual , predicted , weights = ( 0.3 , 0.iii , 0.3 , 0 ) ) ) print ( 'BLEU-four: %f' % corpus_bleu ( bodily , predicted , weights = ( 0.25 , 0.25 , 0.25 , 0.25 ) ) ) |
We can necktie all of this together and evaluate the loaded model on both the training and exam datasets.
The complete code listing is provided below.
| i 2 3 4 v 6 7 8 ix 10 11 12 thirteen 14 fifteen 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 forty 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 lx 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 | from pickle import load from numpy import array from numpy import argmax from keras . preprocessing . text import Tokenizer from keras . preprocessing . sequence import pad_sequences from keras . models import load_model from nltk . translate . bleu_score import corpus _bleu # load a clean dataset def load_clean_sentences ( filename ) : render load ( open ( filename , 'rb' ) ) # fit a tokenizer def create_tokenizer ( lines ) : tokenizer = Tokenizer ( ) tokenizer . fit_on_texts ( lines ) return tokenizer # max sentence length def max_length ( lines ) : return max ( len ( line . split ( ) ) for line in lines ) # encode and pad sequences def encode_sequences ( tokenizer , length , lines ) : # integer encode sequences X = tokenizer . texts_to_sequences ( lines ) # pad sequences with 0 values X = pad_sequences ( X , maxlen = length , padding = 'post' ) return 10 # map an integer to a word def word_for_id ( integer , tokenizer ) : for word , index in tokenizer . word_index . items ( ) : if index == integer : render word return None # generate target given source sequence def predict_sequence ( model , tokenizer , source ) : prediction = model . predict ( source , verbose = 0 ) [ 0 ] integers = [ argmax ( vector ) for vector in prediction ] target = list ( ) for i in integers : discussion = word_for_id ( i , tokenizer ) if word is None : intermission target . append ( discussion ) return ' ' . join ( target ) # evaluate the skill of the model def evaluate_model ( model , tokenizer , sources , raw_dataset ) : actual , predicted = list ( ) , listing ( ) for i , source in enumerate ( sources ) : # translate encoded source text source = source . reshape ( ( one , source . shape [ 0 ] ) ) translation = predict_sequence ( model , eng_tokenizer , source ) raw_target , raw_src = raw_dataset [ i ] if i < x : impress ( 'src=[%s], target=[%southward], predicted=[%s]' % ( raw_src , raw_target , translation ) ) actual . append ( [ raw_target . split ( ) ] ) predicted . suspend ( translation . divide ( ) ) # calculate BLEU score print ( 'BLEU-1: %f' % corpus_bleu ( actual , predicted , weights = ( one.0 , 0 , 0 , 0 ) ) ) print ( 'BLEU-2: %f' % corpus_bleu ( actual , predicted , weights = ( 0.5 , 0.5 , 0 , 0 ) ) ) print ( 'BLEU-3: %f' % corpus_bleu ( actual , predicted , weights = ( 0.three , 0.three , 0.three , 0 ) ) ) print ( 'BLEU-4: %f' % corpus_bleu ( actual , predicted , weights = ( 0.25 , 0.25 , 0.25 , 0.25 ) ) ) # load datasets dataset = load_clean_sentences ( 'english-german-both.pkl' ) train = load_clean_sentences ( 'english language-german-train.pkl' ) test = load_clean_sentences ( 'english-german language-examination.pkl' ) # prepare english tokenizer eng_tokenizer = create_tokenizer ( dataset [ : , 0 ] ) eng_vocab_size = len ( eng_tokenizer . word_index ) + ane eng_length = max_length ( dataset [ : , 0 ] ) # fix german tokenizer ger_tokenizer = create_tokenizer ( dataset [ : , 1 ] ) ger_vocab_size = len ( ger_tokenizer . word_index ) + 1 ger_length = max_length ( dataset [ : , one ] ) # prepare information trainX = encode_sequences ( ger_tokenizer , ger_length , train [ : , i ] ) testX = encode_sequences ( ger_tokenizer , ger_length , test [ : , 1 ] ) # load model model = load_model ( 'model.h5' ) # test on some preparation sequences print ( 'train' ) evaluate_model ( model , eng_tokenizer , trainX , train ) # test on some test sequences print ( 'exam' ) evaluate_model ( model , eng_tokenizer , testX , test ) |
Running the instance get-go prints examples of source text, expected and predicted translations, every bit well as scores for the training dataset, followed by the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average event.
Looking at the results for the test dataset showtime, we tin see that the translations are readable and generally correct.
For example: "ich bin brillentrager" was correctly translated to "i vesture glasses".
We can also run across that the translations were not perfect, with "hab ich nicht recht" translated to "am i fat" instead of the expected "am i wrong".
We can likewise encounter the BLEU-4 score of about 0.45, which provides an upper jump on what we might expect from this model.
| src=[er ist ein blodmann], target=[hes a jerk], predicted=[hes a jerk] src=[ich bin brillentrager], target=[i vesture spectacles], predicted=[i wear glasses] src=[tom lid mich aufgezogen], target=[tom raised me], predicted=[tom tricked me] src=[ich zahle auf tom], target=[i count on tom], predicted=[ill call tom tom] src=[ich kann rauch sehen], target=[i can see smoke], predicted=[i can help y'all] src=[tom fuhlte sich einsam], target=[tom felt lonely], predicted=[tom felt uneasy] src=[hab ich nicht recht], target=[am i wrong], predicted=[am i fat] src=[gestatten sie mir zu gehen], target=[permit me to go], predicted=[do me to become] src=[du hast mir gefehlt], target=[i missed y'all], predicted=[i missed you] src=[es ist zu spat], target=[information technology is too late], predicted=[its too late] BLEU-one: 0.844852 BLEU-2: 0.779819 BLEU-3: 0.699516 BLEU-4: 0.452614 |
Looking at the results on the test set, do see readable translations, which is not an easy task.
For example, we meet "tom erblasste" correctly translated to "tom turned pale".
We also see some poor translations and a adept example that the model could suffer from further tuning, such equally "ich brauche erste hilfe" translated as "i need them you" instead of the expected "i demand first aid".
A BLEU-4 score of about 0.153 was achieved, providing a baseline skill to improve upon with further improvements to the model.
| src=[mein hund hat es gefressen], target=[my dog ate it], predicted=[my dog is tom] src=[ich hore das telefon], target=[i hear the phone], predicted=[i want this this] src=[ich fuhlte mich hintergangen], target=[i felt betrayed], predicted=[i didnt] src=[wer scherzt], target=[whos joking], predicted=[whos is] src=[wir furchten uns], target=[were afraid], predicted=[nosotros are] src=[reden sie weiter], target=[keep talking], predicted=[go along them] src=[was fur ein spa], target=[what fun], predicted=[what an fun] src=[ich bin auch siebzehn], target=[im too], predicted=[im so expert] src=[ich bin dein vater], target=[im your father], predicted=[im your your] src=[ich brauche erste hilfe], target=[i need kickoff aid], predicted=[i need them you lot] BLEU-1: 0.499623 BLEU-2: 0.365875 BLEU-3: 0.295824 BLEU-4: 0.153535 |
Extensions
This section lists some ideas for extending the tutorial that yous may wish to explore.
- Data Cleaning. Dissimilar data cleaning operations could be performed on the data, such equally not removing punctuation or normalizing case, or perhaps removing duplicate English phrases.
- Vocabulary. The vocabulary could be refined, peradventure removing words used less than 5 or 10 times in the dataset and replaced with "unk".
- More than Data. The dataset used to fit the model could be expanded to 50,000, 100,000 phrases, or more.
- Input Society. The lodge of input phrases could be reversed, which has been reported to lift skill, or a Bidirectional input layer could be used.
- Layers. The encoder and/or the decoder models could be expanded with additional layers and trained for more epochs, providing more representational capacity for the model.
- Units. The number of memory units in the encoder and decoder could be increased, providing more than representational capacity for the model.
- Regularization. The model could employ regularization, such every bit weight or activation regularization, or the use of dropout on the LSTM layers.
- Pre-Trained Word Vectors. Pre-trained word vectors could be used in the model.
- Recursive Model. A recursive formulation of the model could be used where the side by side word in the output sequence could be provisional on the input sequence and the output sequence generated so far.
Further Reading
This department provides more resources on the topic if you are looking to go deeper.
- Tab-delimited Bilingual Sentence Pairs
- German language – English language deu-eng.zip
- Encoder-Decoder Long Short-Term Memory Networks
Summary
In this tutorial, yous discovered how to develop a neural machine translation system for translating German language phrases to English.
Specifically, you learned:
- How to clean and gear up data ready to train a neural machine translation system.
- How to develop an encoder-decoder model for automobile translation.
- How to apply a trained model for inference on new input phrases and evaluate the model skill.
Practice you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Note: This mail service is an excerpt chapter from: "Deep Learning for Natural Linguistic communication Processing". Accept a look, if yous want more step-by-step tutorials on getting the most out of deep learning methods when working with text data.
Develop Deep Learning models for Text Data Today!

Develop Your Ain Text models in Minutes
...with only a few lines of python code
Discover how in my new Ebook:
Deep Learning for Tongue Processing
Information technology provides self-study tutorials on topics similar:
Purse-of-Words, Word Embedding, Language Models, Explanation Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.
See What's Inside

How To Add Letter To Edge In Graphviz In Python,
Source: https://machinelearningmastery.com/develop-neural-machine-translation-system-keras/
Posted by: sanderslawen1948.blogspot.com
0 Response to "How To Add Letter To Edge In Graphviz In Python"
Post a Comment